匹配涉及到的类为Regexp, RegexpError, 在匹配过程中涉及到的方法为match, =~, !~,具体用法如下
基本用法
#Regexp的表示方式
Regexp.new("xx") #=> /xx/
%r(xx) #=> /xx/
%r<xx> #=> /xx/
%r!xx! #=> /xx/
%r|xx| #=> /xx/
#"=~"方法返回匹配的第一个字符的字符下标
/xx/ =~ "ooxx" #=>2, 在第三个字符开始配置,所以返回下标2
/xx/ =~ "oo" #=>nil, 若不匹配,返回为nil
"ooxx" =~ /xx/ #=>2, Regexp和String类都有“=~”实例方法
#"match"方法返回MatchData的实例对象,Regexp和String类都有match方法
str = /(.)(.)(.)/.match("abc") #=>#<MatchData "abc" 1:"a" 2:"b" 3:"c">
str[0] #=>"abc"
str[1] #=>"a"
"xx".match(/oo/) #=> nil, 不匹配返回nil
#"!="返回true或者false
"xx" != /xx/ #=>true
"xx" != /00/ #=>false
元字符:用于匹配字符串的专用字符,区别于普通字符
#元字符
. 可以匹配任意一个字符,但是无法匹配换行符
[...] 是字符组,可以匹配任意一个中括号括起来的字符,准确是满足要求的第一个字符
[^...] 排除字符组,可以匹配任意一个字符组以外的字符
#元字符等价用法
\d 等价 [0-9] 即是匹配任意一个数字
\D 等价 [^0-9]
\w 等价 [0-9a-zA-Z_] 包括下划线
\W 等价 [^0-9a-zA-Z_]
\s 等价 [\f\n\r\t\v] 任意一个空白字符
\S 等价 [^\f\n\r\t\v] 任意一个非空白字符
#上面的字符都是在[]中间,都是匹配其中的任意一个字符,是一个字符,这个比较重要
#贪婪匹配(greedy match),匹配尽了能多的字符
* 大于等于0次
+ 大于等于1次
?0次或者1次
{min, max}指定最大和最小次数
{integer}指定固定次数
{min, }指定最小次数
{ , max}指定最大次数
#懒惰匹配(lazy match),匹配的次数满足下限就行
*? 0次
+? 1次
?? 0次
{min, max}? min次
示例
针对下面对比示例的说明,其中str.match(/\d+/)和str.match(/\d*/),其中*是满足匹配大于等于0次,+是大于等于1次,前者在匹配h时候,不匹配,但是*可以匹配0次,于是直接返回,匹配为空,后者必须匹配大于等于1次,直到数字1才匹配,因此尽可能多匹配,直到不能匹配为止,str.match(/\d+/)相当于str.match(/\d\d*/)。
#str = "hello world! 123"
匹配任意字符: str.match(/.*/) #<MatchData "hello world! 123">
不匹配数字:str.match(/.+[^\d]/) #<MatchData "hello world! ">
匹配到!为止 str.match(/.{1,12}/) #<MatchData "hello world!">
只匹配数字 str.match(/\d+/) #<MatchData "123">
对比 str.match(/\d*/) #<MatchData ""> 匹配为空,对比说明如上所示
str.match(/\w*/) #<MatchData "hello"> 尽可能多匹配,直到不能匹配为止
str.match(/\w+?/) #<MatchData "h"> 匹配多次的下限1次
str.match(/\w*?/) #<MatchData ""> 匹配多次的下限0次
str.match(/\w?/) #<MatchData "h"> 匹配1次
str.match(/\w??/) #<MatchData ""> 匹配下限,0次
str.match(/\w{1,6}/) #<MatchData "hello">, 按照max次数取,直到不能匹配为止
str.match(/.{1,6}/) #<MatchData "hello ">, 匹配max次数取,包括空格
str.match(/.{1,6}?/) #<MatchData "h ">, 取下限值,1次
分组
(...)捕获型括号,用于分组,捕获到的值存储在$1..变量中,可以用于反向引用
(<name>...)命名捕获
(?:...)非捕获型括号,只用于分组,不会存储到变量中
(?#) 用于注释
(?imaxdau-imx:...)修饰符,-i -m -x关闭对应的修饰符
多选分支
| 管道符,用于多选分支
?...|... 条件判断
示例
str = "hello world "
str.match(/\w+/) #<MatchData "hello">
str.match(/\w+ /) #<MatchData "hello "> 包括空格
str.match(/\w+ \w /) #<MatchData "hello world "> 匹配全部
str.match(/(\w+ ){2}/) #<MatchData "hello world " 1:"world"> 全部匹配,后面1代表捕获到$1中,捕获最后一个匹配的值world
不想捕获,str.match(/(?:\w+ ){2}/) #<MatchData "hello world ">
str.match(/h(e|o|0)llo/) #<MatchData "hello" 1:"e"> 使用管道符
str.match(/h(?:e|o|0)llo/) #<MatchData "hello"> 使用非捕获
str.match(/h[eo0]llo/) #<MatchData "hello">多选分支的替代方式
#反向引用示例
str = "go go"
str.match(/(\w+)\s\1/) #<MatchData "go go" 1:"go"> 1表示第一次匹配的值,即使用后面的1引用前面的(\w+)
str = "go to go to"
str.match(/(\w+)\s(\w+)\s\1\s\2/) #<MatchData "go to go to" 1:"go" 2:"to">
#命名捕获结合反向引用示例
str = "go to go to"
str.match(/(?<go>\w+)\s(?<to>\w+)\s\k<go>\s\k<to>/) #<MatchData "go to go to" go:"go" to:"to">,反向引用使用\k
str.match(/(?'go'\w+)\s(?'to'\w+)\s\k'go'\s\k'to'/) #<MatchData "go to go to" go:"go" to:"to">,<使用’代替
#如上使用命名捕获,可以用$1和$2获得捕获的值,但是不能通过命名名称‘go’,'to'获得命名值,如果要通过后者获得值,需要使用=~
str =~ (/(?'go'\w+)\s(?'to'\w+)\s\k'go'\s\k'to'/) #可以通过go和to获得命名值
#named_captures
re = /(?'go'\w+)\s(?'to'\w+)\s\k'go'\s\k'to'/
re.named_captures #=>{"go"=>[1], "to"=>[2]}
re.names #=>["go", "to"]
#条件判断示例
str = "FoO"
reg = /([A-Z]?)[a-z](?(1)[A-Z]|[a-z])/ #意思:最后一个括号,如果捕获到则大写,没有捕获则小写
str.match(reg) #<MatchData "FoO" 1:"F">
简单锚点
^ 匹配每行的开始
$ 匹配每行的末尾
\b 单词分界符
\B 非单词分界符
\A 字符串起始位置
\Z 字符串的结束,或者新行的开始
\z 字符串结束
\G 匹配开始位置
#示例
str = "123 hello 456"
str.match(/^\d+/) #<MatchData "123">
str.match(/\d+$/) #<MatchData "456">
str.match(/^\d+$/) #nil
"123 456".match(/^\d+$/) #nil ,必须是连续的数字
str.match(/\bhello\b/) #<MatchData "hello"> 单词分界符的使用
"hell123".match(/^[^0-9]/) #<MatchData "h">,区别“^”在[]之内还是之外
/\b/ 与 /[\b]/ 区别,[]之外表示单词分界符,之内表示特殊字符退格符
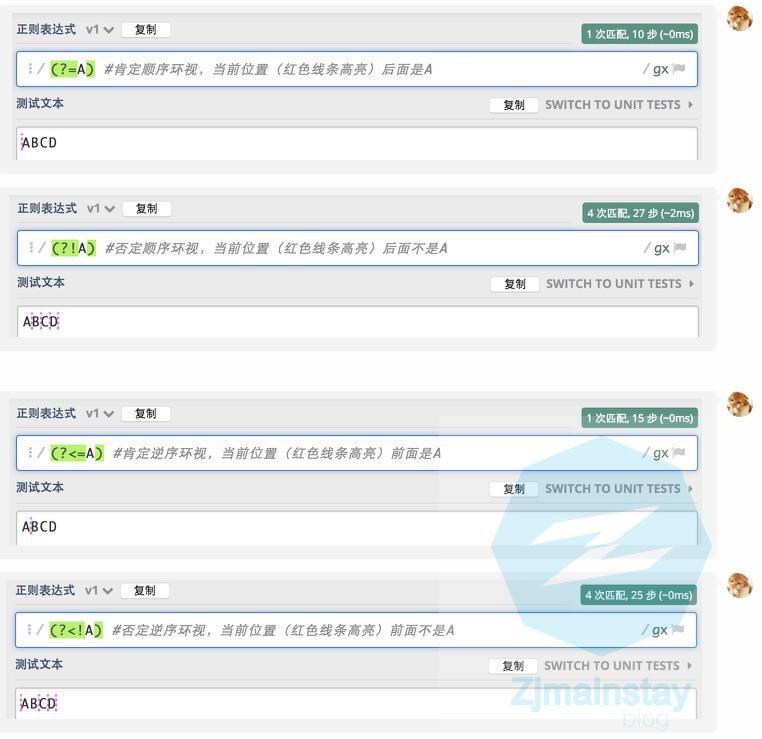
复杂锚点:环视(零宽断言)
#肯定环视
(?=...) 正向环视,从左往右
(?<=...)逆向环视,从右往左
#否定环视
(?!...)正向否定环视,从左往右
(?<!...)逆向否定环视,从右往左
简单环视示例
例如,对于源字符串ABC,正则(?=A)[A-Z]匹配的是:
1. (?=A)所在的位置,后面是A
2. 表达式[A-Z]匹配A-Z中任意一个字母
根据两个的先后位置关系,组合在一起,那就是:
(?=A)所在的位置,后面是A,而且是A-Z中任意一个字母,因此,上面正则表达式匹配一个大写字母A。
从例子可以看出,从左到右,正则分别匹配了环视(?=A)和[A-Z],由于环视不消耗正则的匹配字符,因此,[A-Z]还能对A进行匹配,并得到结果
str = "hello world"
str =~ /(?=world)/ #=>,匹配的是一个位置,返回值为6
str.match(/(?=world)/) #=><MatchData ""> 匹配的是一个位置,在空字符串那里
str.match(/(?=world)\w+/) #=><MatchData "world">
str = "10000000"
re = /(?<=\d)/
str.sub(re, ",") #=>1,0000000
str = "1000000000"
re = /(?<=\d)(?=(\d\d\d)+(?!\d))/ #解释,第一个为数字,后面三个数字为一组,后面不
str.gsub(re, ',') #=>1,000,000,000
example
#url
/https?:\/\/[\S]+/
#email
/\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i